Data has become one of the most valuable assets that any business can have, so proper and secure storage is of paramount importance. This is where data warehousing comes in, a rigorous process of structuring and storing historical data and providing easy access to it for analysis and business development.
At MeDirect, we are currently undergoing a significant transformation in this area. Our ‘central’ warehouse of data is currently based on PostgreSQL (Postgres), an RDMS system with high availability, and located on-premise; an on-premise Hadoop cluster and other related services such as Hive also form part of the current Data Platform, and these are used to store some high volume and/or unstructured data sets.
As part of MeDirect’s continuous approach to digital transformation, we are now working towards migrating from this fully on-premise data platform to a cloud data platform.
Why Opt for Cloud-based Solutions?
The growing information requirements of rapidly changing business models need a robust yet scalable and adaptable data architecture. And yet, many companies are still veering towards cloud-based solutions which are arguably the most disruptive drivers of a radically new data architecture approach.
Cloud computing signals a shift away from the supply of software and its execution on local servers, and toward the use of shared data centres and software-as-a-service solutions hosted by platform providers such as Amazon, Google, and Microsoft.
It should be acknowledged that this model adjusts to unanticipated user needs through the cloud’s shared infrastructure, which offers greater economies of scale, high scalability and availability, and pay-per-use pricing.
So, with such cloud-based solutions being readily available, why should companies consider modernizing their data architecture and adopt a more innovative future-proof approach?
In addition to IT cost reductions and productivity increases, modernization of data architecture can decrease regulatory and operational risk while also enabling the introduction of new capabilities and services.
McKinsey identifies 6 foundational steps towards the adoption of innovative future-proof data architecture, as presented in Figure 1.
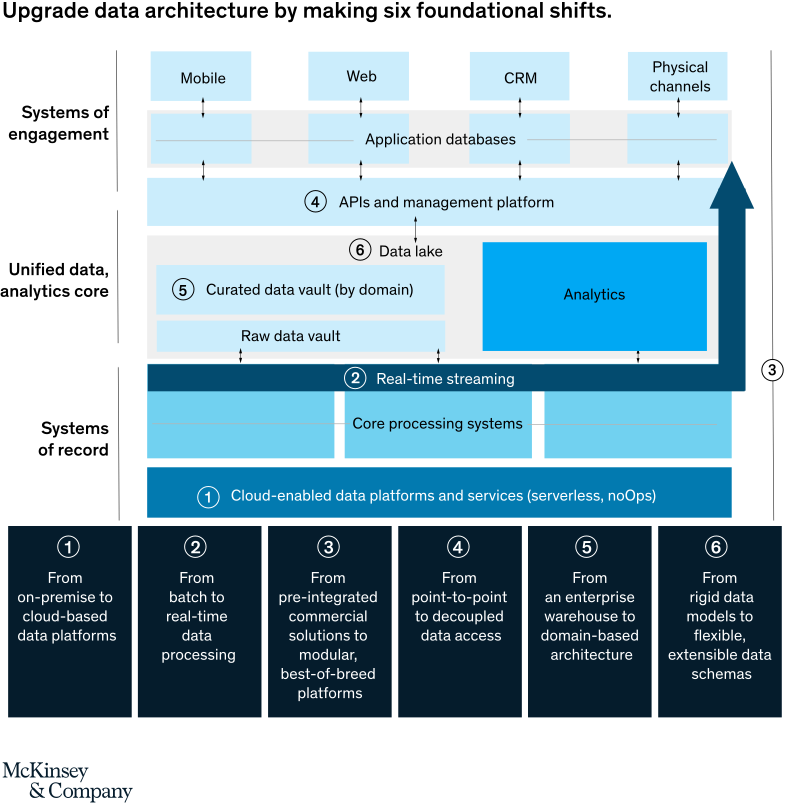
Migration to Cloud-based Data Warehouse
Migration Goals
Every strategy needs to consist of a set of objectives or goals which define success. At MeDirect, we considered the following goals when working upon this cloud data warehouse migration project:
- Improving the overall data warehouse performance, achieved through:
- Improving data loading performance
- Improving complex querying performance
- Enabling concurrent users
- Increase agility and productivity, by:
- Enabling elasticity and scalability
- Improving data engineering efficiency
- Lowering of costs, by:
- Lowering the Total Cost of Ownership through a pay-per-use model
- Reducing administration overheads
- Improving platform availability, by having:
- Service-level agreements in place
- A high availability platform
- Consolidating the data storage layer, by
- Consolidating data storage layer, currently in Postgres and Hadoop respectively.
Selecting a Cloud Data Warehouse – Snowflake
There are various cloud data warehouses available on the market, among which Snowflake, Amazon Redshift, and Azure Synapse.
In order for our team to select a cloud data platform, we conducted our internal evaluation and Proof of Value. This involved performing various functional and non-functional tests that cover a wide range of features such as integration, data loading, querying, security, ease-of-use, and performance.
After a thorough evaluation phase, Snowflake was selected as our cloud data warehouse.
Snowflake is highly reputed in the cloud data warehouse space. It is described as a cloud-agnostic solution, so it is available on all three cloud providers: Azure, Google Cloud Platform (GCP), and Amazon Web Services (AWS).
After careful consideration, our team decided on Snowflake on Azure.
Other distinctive features of Snowflake that made it particularly suitable for our needs include the separation between compute and storage. This would enable us to scale up resources when we need large amounts of data to be loaded or queried faster, and scale back down when the process completes without service disruptions.
Moreover, with Snowflake, we can execute different workloads on separate clusters called virtual warehouses. This enables the concept of concurrency, which will be covered later in this post.
Other Snowflake key features include its near-zero administration, reducing support from DBA or IT teams. In addition, it is also capable of handling both structured and semi-structured data in the same destination by utilising a schema on read data type called VARIANT.
Finally, MeDirect takes security very seriously in all its operations, and Snowflake’s wide array of security features ticked all our boxes.
Migration Strategy
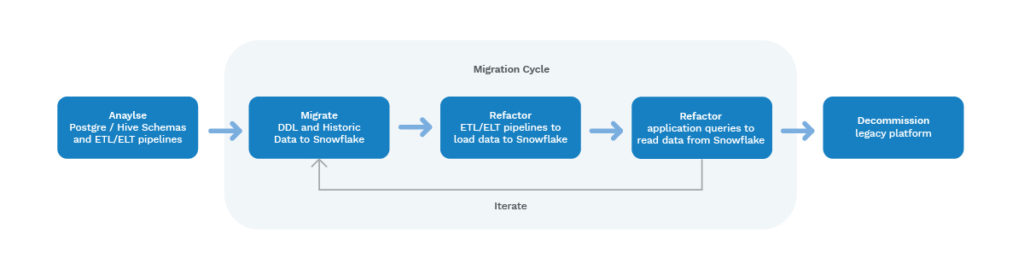
The approach to migrating over to Snowflake involved a lift and shift, as illustrated in figure 3.
This consisted of the migration of the schemas and tables without major changes in the data structure. Our main aim was to focus and prioritise the migration, which was key for the successful transfer of our large and complex data warehouse and its large number of dependencies. This approach will help our long term strategy to continuously improve our existing data warehouse by centralising data logic according to business needs. Moreover, it will enable us to improve the overarching data structure on the new platform, thus optimising data retrieval, reporting and analytic processes.
Retaining the same data structures enabled data consumers to switch to the new system with relative ease, and without requiring significant changes in their queries. This approach also enabled us to easily reconcile the data between the old system and the new one and run them in parallel to gain confidence in the migration before decommissioning the old system.
The migration was performed in phases (or cycles) for agility. This allowed our data consumers to immediately start migrating to the new system as the data migration was ongoing. Each phase consisted of a group of datasets and ETL/ELT processes which were prioritised for migration based on transfer complexity and their overall business value. As such, data sets with low complexity and high business value were prioritised first.
An initial analysis was performed on the Postgres and Hive schemas and data pipelines, to determine all the data sets to be migrated and ETL/ELT jobs to be refactored. During the analysis, all the schemas and data pipelines were documented, and a data lineage exercise was conducted to identify BI application dependencies. Any data sets which were on the old platform but were classified as having become redundant were excluded from the migration.
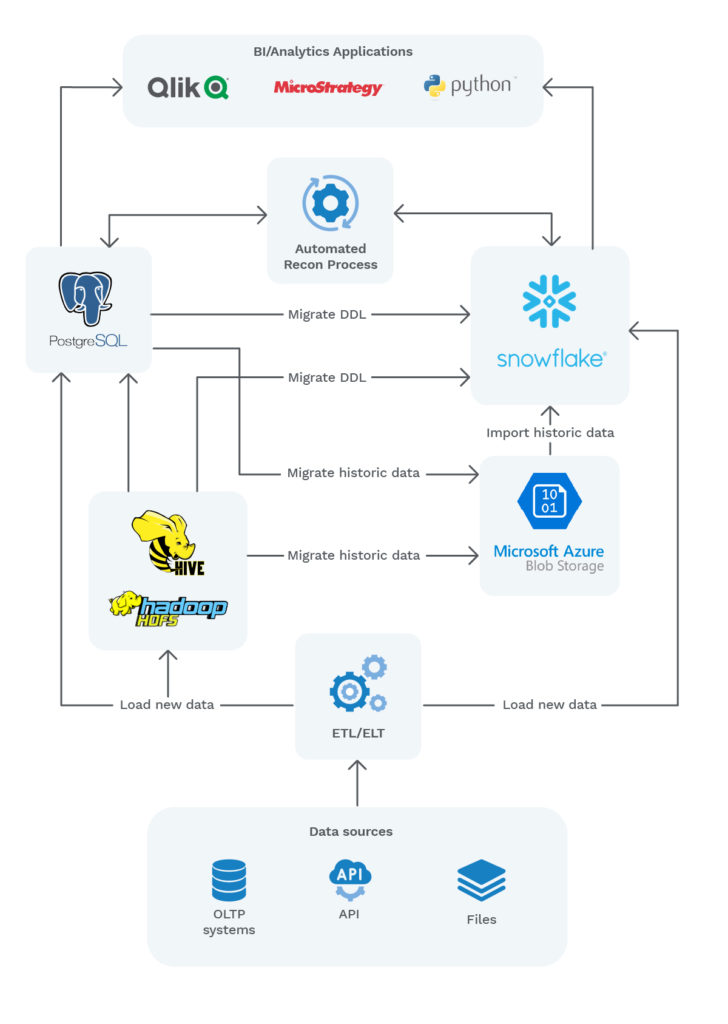
DDL and Historic Data Migration
Data Definition Language, or DDL, refers to the language that is used to build or modify the structure of database objects. As the first step for each migration cycle, we generated the Postgres and Hive DDL scripts related to the respective migration cycle and executed them in Snowflake. This created all the Postgres and Hive schemas and their objects in Snowflake.
Some changes were required in the DDL scripts to make them compatible with Snowflake, such as converting data types to the ones supported in Snowflake. All Snowflake DDL scripts were placed in a dedicated Git repository for source control management.
After migrating the schemas, our team then migrated the historic data from Postgres and from the Hadoop file system to Snowflake by following the below steps:
- Dump table data to compressed CSV files (‘|’ delimited) using Postgres ‘COPY TO’ command. Data that exceeded 50GB was split by year into separate files to facilitate file transfer. This step was only required for Postgres data, as Hadoop data was already stored in files.
- Upload files to Azure Blob Storage using AzCopy, a command-line tool that can be used to upload or download files from, or to Azure Blob Storage.
- Import data into Snowflake tables from Azure Blob Storage by using a mapped external stage to reference the external data files, and executing a ‘COPY INTO’ command on Snowflake.
- Perform data checks to ensure the migration was successful. Such tests compared the schema structure and data in Snowflake. Data checks performed included:
- Simple check if database objects exist on Snowflake
- Structure comparison of each table
- Record count of each table
- Distinct count of each string column
- Sum of each numeric column
- Thorough data comparison for random date periods
ETL/ELT Pipeline Refactoring
ETL stands for Extraction, Transformation, and Load, and is the process used to extract data from different sources, transform the data, and load it into the data warehouse. ELT is similar to ETL, but the data transformations are performed after the data has been loaded.
As part of our digital transformation process, all the ETL/ELT processes which load data into Postgres and/or Hadoop needed to be refactored to also load data into Snowflake. A parallel load was performed in both the old and new systems to eliminate downtime and interruptions during the migration period.
All our ETL processes are developed using Talend, an ETL tool that supports data loading to Snowflake via native connectors. This made it possible for us to simply replicate the output of the Talend jobs, which were previously loading data to Postgres to parallel load data into Snowflake.
The replicated output flow was parameterised so that we could easily activate or deactivate data loading into Postgres or Snowflake by simply updating a variable. All data commits and rollbacks were done as a post-job task, to mitigate the risk of having data discrepancies between the two systems should any failures occur during data loading.
In contrast to the ETL pipelines, ELT jobs that load data to Hadoop/Hive had to be completely refactored, and new jobs were developed to be able to load data to Snowflake.
Ongoing Data Reconciliation during Parallel Loading
An automated data reconciliation process was developed by our team to ensure that the Postgres and Snowflake platforms were kept in sync during the parallel loading period. The process was metadata-driven and scheduled to run daily. All check results were logged, and notifications were raised for any data discrepancies identified.
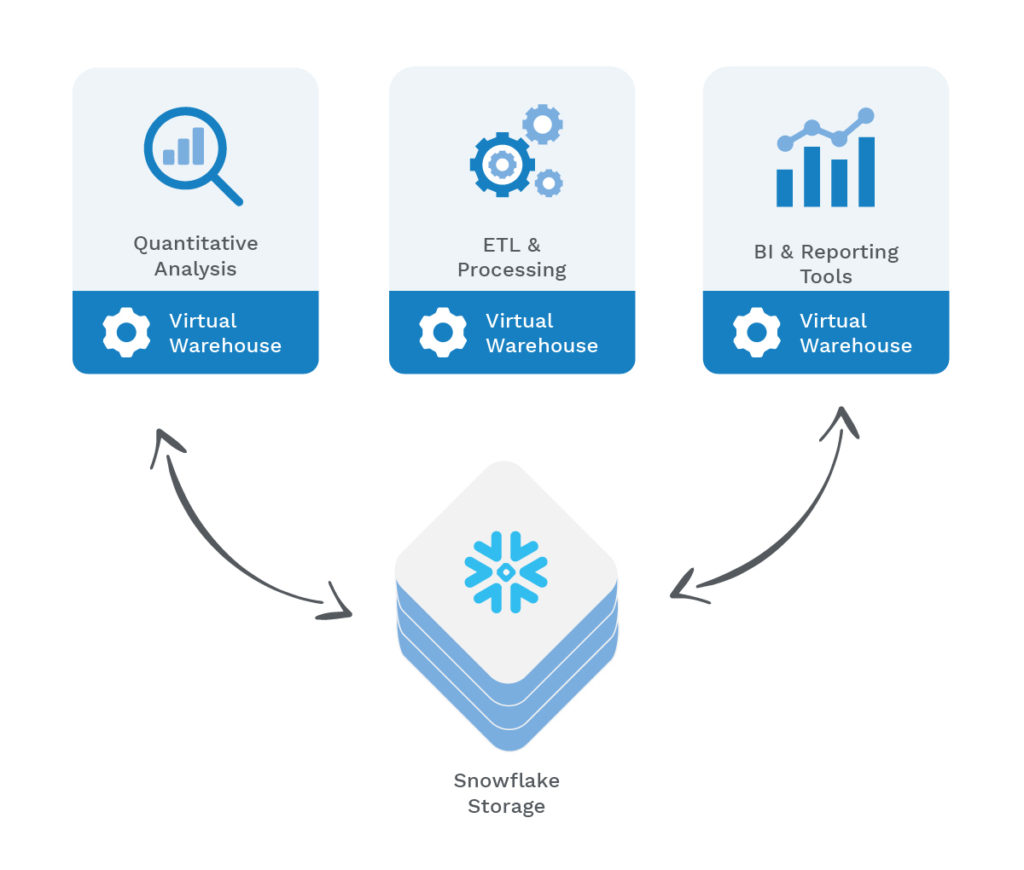
Performance Improvements through Virtual Warehouses
The Snowflake compute layer consists of virtual warehouses that execute data processing tasks that are required for running SQL statements. Each virtual warehouse (or cluster), can access all the data in the storage layer, then work independently so the warehouses do not share, or compete for, compute resources.
This enables non-disruptive and automatic scaling, which means that while queries are running, compute resources can scale without the need to redistribute or rebalance the data in the storage layer. Moreover, allocating functions to separate virtual warehouses ensures that processes do not compete for the same compute resources, so they have no impact on each other.
We leveraged Snowflake virtual warehouse by having different functions assigned to a separate virtual warehouse as shown in Figure 4 below. This was a real game-changer for our team and our overall performance.
Key Benefits of this New System
This year-long project by our engineering team at MeDirect has yielded a lot of advantages, as our team continues working towards consistent digital transformation in our systems. Some of these benefits include:
- Fewer administration overheads – more optimisation translates to less internal staff hours dedicated to admin and managing of clusters, and other areas of responsibility now handled by Snowflake.
- Increased agility – working with a provider such as Snowflake, we now have better flexibility in terms of increased storage, RAM, and other components on a cloud-based system.
- Better elasticity – this is built-in into the cloud, so you can scale up or down according to your requirements which also include specific time windows during the day.
- Flexible costs – Overall costs for this system are incurred for the compute and storage actually utilised, and not resources that are only utilised for a few minutes of every day.
- Minimal start-up costs – This system avoids the large initial investment required of an on-premise system, so it is OpEx rather than CapEx+ that frees up the team’s time, as they are not occupied with running and maintaining the system.
- Increased performance – Snowflake is purely built of data warehousing and optimisation in terms of architecture specifically used for the requirements of data warehousing.
- Saves time – Compute processes can run in parallel in the warehouse, using virtual warehouses, so that they run separately but on the same data.
- Faster queries – Running a query on Snowflake is actually much faster than Postgres.
- Independent data loading – As our data engineering team is constantly running data loading processes, this new system does not impact other processes internally.
Looking Ahead – Near Real-time Data Processing
The frequency of updating data warehouse tables is growing, as demand for real-time analytic findings on data warehouses also increases and the time window for completing an ETL task is diminishing (to minutes or seconds).
The architecture of data warehouses and ETL maintenance processes is influenced by factors such as data freshness and efficiency. In near real-time data processes, incremental data capture approaches such as Change Data Capture (CDC) have been frequently utilized to transmit deltas. These insertions, deletions, and or updates from source tables to destination warehouse tables prevent recomputing everything from the start.
There are 4 key attributes that generally define a near-real-time data architecture, specifically:
- Low latency – Latency is defined as the time lag between when a transaction is executed in the transactional source system, and when it is loaded into the data warehouse system. A near-real-time system should have extremely minimal latency, preferably in minutes, and give the most up-to-date data for business analysis.
- High availability – Typical near-real-time source systems such as streaming datasets are time-sensitive, which implies that the data created by them is only accessible for a short length of time. To eliminate inconsistencies, the data warehouse infrastructure should be able to deal with such sources, while also making the most use of data distribution and replication mechanisms.
- Minimum disruptions – It is critical for near-real-time systems to place as little strain on source systems as possible throughout the extraction process, and to use efficient data loading procedures to prevent affecting data warehouse customers’ quality of service.
- High scalability – Scalability in data warehouse settings refers to a system’s capacity to react to a rapid rise or drop in source data volume without affecting overall environmental performance. Since the bulk of its sources may create variable data volumes, near-real-time systems must be extremely scalable.
Our collaboration with Snowflake has also been a runaway success, such that Account Director Fernando Cortes stated that it was a pleasure working with MeDirect in their journey to the cloud.
“MeDirect is a perfect example of how native cloud architectures can accelerate projects and provide value to the business.”
“They were highly engaged from the beginning, providing really valuable feedback to the team, and showing an advanced knowledge of Snowflake”, he went on to say.
The next step in our data platform evolution is to start transitioning from largely batch-based data pipelines to near-real-time pipelines. In doing so, our data engineers will capitalise on Snowflake functionality and compute for continuous data loading and data transformations.
A little about us…
