 - HERO IMAGE")
Introduction
When it comes to the software release lifecycle, there are several processes that can be applied prior to releasing the product to the end-user following testing, upgrades and bug fixes. These can involve various stages of analysis, code deployment, creating the build, testing, deployment, and more.
One of the more common approaches to this lifecycle is Continuous Deployment (CD), which uses automated testing in order to validate whether the changes made to a codebase are correct and stable enough for the immediate autonomous release to a production environment.
And yet, many developers and experts in this field will readily acknowledge that the overall software release cycle has greatly evolved over time. Gone are the days when developers used to move code from one machine to another and manually testing to see if it meets expectations. This process was not only highly prone to errors but also very resource-intensive.
Dev tools have now shifted focus towards an automated process of deployment, which frees up resources considerably and allows companies to focus on other key business needs. The same can be said for our systems at MeDirect, which has seen a substantial overhaul to transition our operations towards a more automated and efficient approach.
In this article, we will be providing readers with an insight into how we have updated our method of working, and how this is allowing us to achieve better results while still delivering a high-quality product through a streamlined process. This is our journey to GitOps, and how we are implementing Continuous Deployment for our cloud-native applications.
An initial Rolling Release system
The majority of software developers have migrated towards a rolling release or continuous delivery system, where their software or applications are provided with regular updates. This contrasts significantly with the now outdated point release development approach where new software versions are reinstalled over previous versions.
Now, it is very important to differentiate between Continuous Deployment and Continuous Delivery in the context of this article. Despite the fact that both processes can be abbreviated to CD, it is important to point out that delivery is the starting point that leads to deployment. During the delivery phase, developers will work upon any code changes that are then packaged and moved to a production environment where it waits for approval before it is deployed. During deployment, the package is opened and tested, and should it pass inspection it will be automatically deployed to production.
In the past, developers at MeDirect used Jenkins and Octopus Deploy as the basis for their deployments, which were both used to deploy applications in a CI/CD onto virtual machines. The CI/CD method is a frequently utilised method of delivering applications to end-user customers by introducing automation into the stages of development.
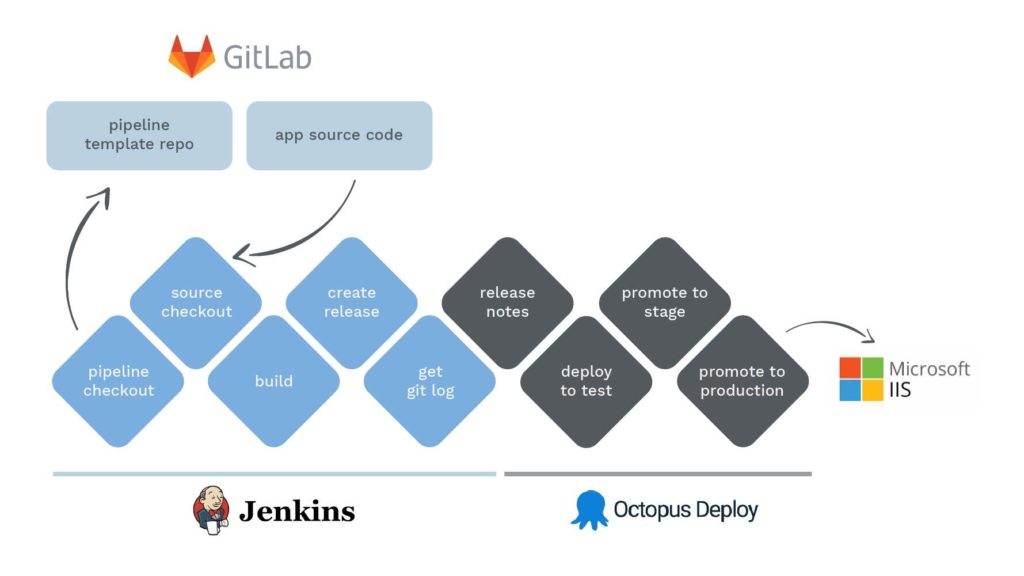
As part of this rolling release system, CI/CD attributes concepts of continuous integration, continuous delivery, and continuous deployment, which have become very popular in alleviating the problems most developers face when integrating new code into existing systems.
To be more specific, CI/CD introduces ongoing automation and continuous monitoring through the software release lifecycle. The entire process of integration, testing, delivery, and deployment become connected practices in what is mainly referred to as the CI/CD pipeline. Each time one of our developers would commit to an action, the pipeline would trigger, compile the information, generate a package, notify Octopus to generate a release, work within the load balancers, and deploy the package if it passes inspection.
This rolling release system with both Jenkins and Octopus Deploy was a very useful approach for some time, but as it was based on VMs, it was deemed as being too slow. Furthermore, in situations that required rollbacks, it proved to be a little clumsy as a failsafe should issues have arisen.
As such, we took the decision to update our approach towards Continuous Deployment, which was required even further as our business shifted towards a microservices architecture.
The Era of Microservices
Microservices are becoming an increasingly popular approach to development architecture; complex monoliths are losing their appeal among development teams as they grow in capacity over time and become very difficult to manage and upgrade.
A cost-effective approach to avoid bulky monoliths is to use microservices instead, which can be tailored to a more modern approach of managing human resources. As opposed to a large monolith developed by a specific team that can change over time, an application can now be designed as a composition of different features that are owned by independent teams. Essentially, microservices are “an architectural style that structures an application as a collection of services”.
The microservice architecture enables the rapid, frequent and reliable delivery of large, complex applications. It also enables an organization to evolve its technology stack into one which consists of maintainable and testable constituent parts, owned by smaller teams than previously required, and that are organized around business capabilities.
This gives each team a distinctive approach and specific goals, allowing them to focus on the feature and specialise in it. This also allows each feature to be developed end-to-end, from database to user interface, giving the team a cross-functional approach.
New tools for more pipelines
When our team started working with microservices, we noticed a reduction in response times by our dev-ops team. With around 30 applications coming in and requiring updating at the time of writing, a pattern emerged that showed how each pipeline required around one to two weeks.
Given the heavy requirements that we had with our Jenkins and Octopus Deploy approach, this resulted in a sluggish deployment method. Since several independent microservices can be added to an application, our dev-ops team was struggling to keep up with the rapid deployment rate that these microservices have.
In order to prevent such bottlenecks from hampering our performance, our team decided to adopt a new approach to a new software release lifecycle that included microservice deployment.
Containerisation
The philosophy of containerisation was gradually assimilated into our lifecycle, which had to initially be streamlined with the ongoing process of microservice deployment.
Containerisation refers to a form of operating system virtualisation where applications are run in isolated user spaces called containers, all of which use the same shared operating system. This builds on the foundations that virtualisation has laid through the optimisation of hardware resources, and allows for a new, flexible and cloud-centric approach to building applications.
In fact, containerisation has become the standard for cloud-native application development, allowing teams to make changes to isolated workloads and components without having to make significant changes to the overall application code.
This makes containerisation the ideal solution for working with microservices, as it can allow for the delivery of smaller, single-function modules that work seamlessly to create applications which are more agile and scalable. As such, our dev-ops team would not have to build and deploy a new software version each time a change is made to a specific microservice. In terms of technical setup, we decided to use Kubernetes and Red Hat OpenShift.
Shifting to Kubernetes and OpenShift
Containerisation is often synonymous with technologies such as Kubernetes and OpenShift, which make it possible for companies such as MeDirect to effectively manage microservice deployment.
Our old systems ran containers inside traditional VMs, which led to the bottlenecks we mentioned previously in this article. As such, we installed a test cluster to see how it behaved in terms of security, access control, and also other considerations. The aim was to make the deployment process much simpler with not much thought process behind it – an easily repeatable and replicable process that allows our developers to focus on other key issues in our business.
Kubernetes + OpenShift
Kubernetes is an open-source container-as-a-service (CaaS) framework that acts as an open-source containerisation system that lets developers manage services and workloads. The system automates application deployment, scaling and operations, allowing developers to leverage capabilities such as self-monitoring, process automation, container balancing, storage orchestration, and more.
OpenShift is a family of containerisation technologies based upon Kubernetes and serving as a kind of ‘expansion pack’ to it; in our case Kubernetes acts as the core of distributed systems while Openshift acts as the distribution. It is considered to be both a containerisation software and as a platform-as-a-service (PaaS) that is partly built on Docker, another very popular containerisation platform. OpenShift provides companies with consistent security, built-in monitoring, and of course, full compatibility with Kubernetes.
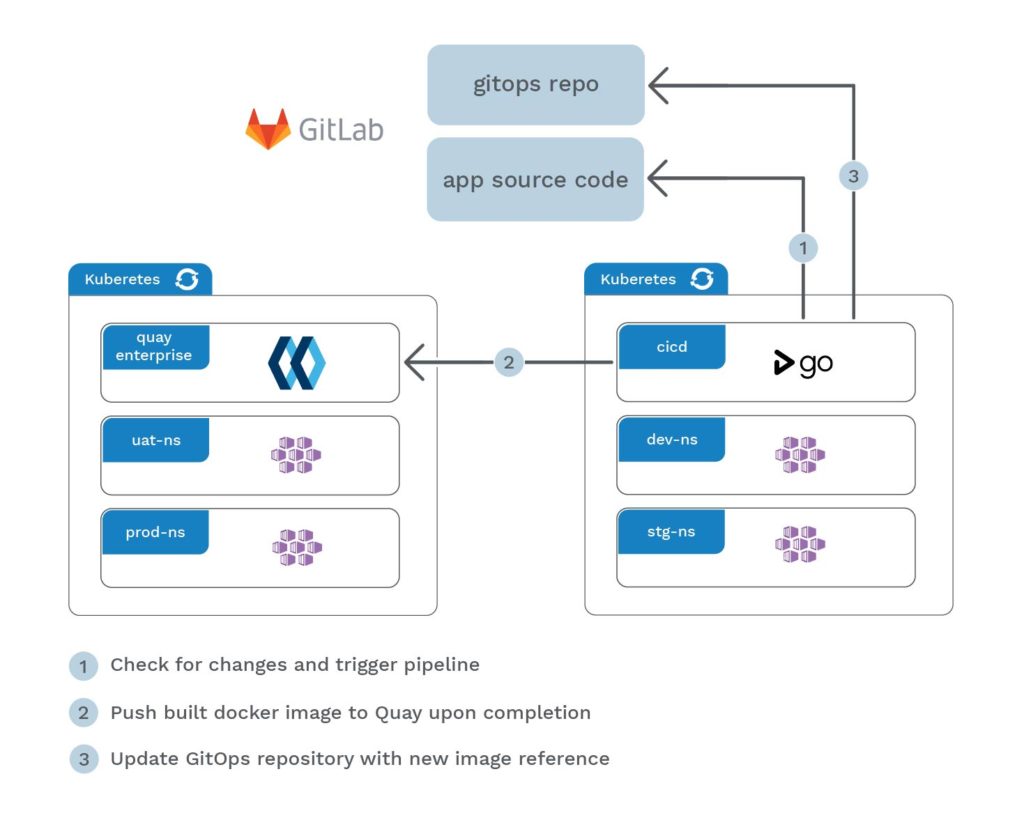
Both container management systems have been a huge asset to MeDirect, with Kubernetes supporting our automatic application deployment, scaling, and operations, and OpenShift providing the necessary container platform that works in tandem with Kubernetes to run applications more efficiently.
In addition, we were also looking into a way to integrate our Continuous Delivery pipeline into Kubernetes using native Kubernetes objects. The idea was to make the experience frictionless and transparent for both DevOps and developers alike.
We trialled a few options such as Helm, which resulted as being too complex for our needs. As such, we tested and settled upon Kustomize, which allows us to have simple scripts that could generate multiple templates based on previously set parameters and components, without the need to have in-depth knowledge of templating
Integrating GoCD into our systems
At this stage, our dev-ops team at MeDirect realised that these tool upgrades meant that we could no longer use Jenkins, so we started looking at GoCD as a reliable alternative for integration with both Kubernetes and OpenShift.
GoCD supports the continuous delivery out of the box as a result of its built-in pipelines, advanced traceability, and value stream visualisation. GoCD provides our team with the flexibility to effectively represent CD pipelines, which when coupled with Kubernetes’ highly programmable delivery infrastructure platform, provides an efficient continuous delivery tool for our infrastructure.
There are several advantages as to why GoCD was selected as a replacement for Jenkins at this advanced stage of our software release lifecycle. It allows for a flexible and easy setup for the deployment pipelines and comes with highly customisable to diverse requirements. In addition, our developers can configure environment variables for each step of the lifecycle with relative ease, giving GoCD an edge over Jenkins in terms of continuous deployment and testing management.
Overall, the decision to integrate GoCD into our systems was very well received, as it could read an entire pipeline very easily, as well as deploy and rollback if needed. We found it to integrate very nicely with Kubernetes and creates agents as needed without requiring input from our team. Instead of working with the 2 Jenkins builders that we previously had, we have now upgraded to an essentially infinite number of builders with GoCD.
Final thoughts on our journey to GitOps
The software release life cycle has changed considerably at MeDirect, as our focus shifted towards new technologies such as microservices and cloud-native applications. This in turn led to the start of our journey to GitOps, a way of implementing continuous deployment for our products.
GitOps focuses on providing a developer-centric experience when operating infrastructure, by using tools that developers are familiar with, which include the CD tools that we mentioned above. Fundamentally, GitOps aims at having a whole system that is managed declaratively and using convergence.
The system contains declarative descriptions of the infrastructure which is required in the production environment, as well as an automated process to make the production environment match with the described state in the repository. Each time the team wants to deploy a new application or release a new update, they would only need to update the repository as the automated process handles everything else.
What started out as a complex and bulky process with Jenkins and Octopus Deploy was essentially reduced to a copy-paste exercise where only a few parameters would require a change. The process of creating staging versions, committing, and pushing to production is automated, freeing up dev team time and allowing for far larger throughput, as well as automated monitoring, which previously was done ad-hoc and manually.
These changes have also been invaluable in our shift towards microservices. When a new microservice is required, most of the processes are automatically included on replication and then modified as needed, saving time that would otherwise be wasted building scripts each time a deployment is needed.
For our microservice needs, GitOps allows for components to be quickly and easily shared between processes and microservices without the need for lengthy and costly human resources at every stage of the build and deployment. Our team now has enough experience to practically generate a model that dictates how an application should be deployed by Kubernetes.
The transitions for our dev-ops team has not been an easy one, with a lot of new tools and processes being introduced. And yet, our deployments are now quicker, cleaner, more efficient, but still come with the same quality that we have always offered.
A little about us…
